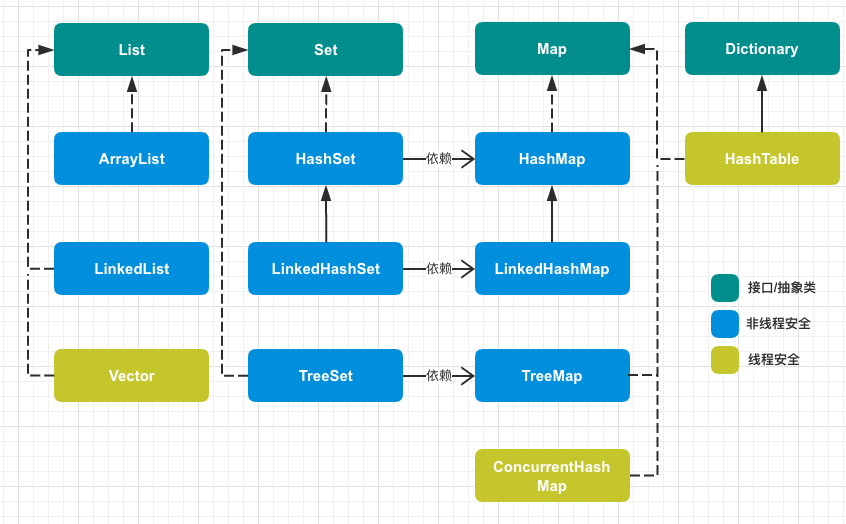
Java集合总结
本文就是Java常见集合的一些总结,包括HashMap、HashSet、HashTable、LinkedHashMap、LinkedHashSet、ArrayList、LinkedList、ConcurrentHashMap等。
本文若无特殊声明,源码都是基于 JDK 8。
1. HashMap¶
HashMap类的定义如下:
常用方法:
public int size()
public boolean isEmpty()
public V put(K key, V value)
public V get(Object key)
public boolean containsKey(Object key)
public boolean containsValue(Object value)
public V remove(Object key)
它具有如下特征:
- HashMap是基于Map接口的非同步实现
- HashMap中key是唯一的,value可以重复;对同一key的
put操作会使新的value替换并返回旧的value - HashMap中允许使用null键、null值;null键数据会放到table[0]上;HashMap最多只允许一条记录的键为null,多次
putnull键数据,会使新的value替换并返回旧的value - HashMap中的元素是无序的
HashMap是使用哈希表来存储数据的。为了解决哈希表的哈希冲突,可以采用这些方法来解决问题:开放定址法、链地址法(拉链法)、再哈希法、建立公共溢出区等方法。开放定址法又包括:线性探测再散列、二次探测再散列、伪随机探测再散列等。Java中HashMap采用了链地址法。
名词解释:
- 开放定址法
当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。
- 线性探测再散列
以增量序列 1, 2, …… , (TableSize - 1) 循环试探下一个存储地址
- 二次探测再散列
以增量序列1, -1, 4, -4 … 循环试探下一个存储地址。
- 伪随机探测再散列
以伪随机数序列为增量试探下一个存储地址
- 链地址法(拉链法)
将全部具有同样哈希地址的而不同keyword的数据元素连接到同一个单链表中。假设选定的哈希表长度为m,则可将哈希表定义为一个有m个头指针组成的指针数组T[0..m-1]。凡是哈希地址为i的数据元素,均以节点的形式插入到T[i]为头指针的单链表中。而且新的元素插入到链表的前端。
在 JDK 7 中,HashMap数据结构为数组+单链表,链表的插入顺序为头插法。在resize过程中,会对每一个节点进行rehash,如果一个桶中有若干个元素在rehash前后都刚好在一个桶中,那么它们之间会出现逆序;且resize过程在多线程环境下容易出现环形链表死循环的问题。
在 JDK 8 中,HashMap数据结构为数组+单链表+红黑树,链表插入顺序为尾插法;且当链表的长度大于8时转换为红黑树;在resize过程中,如果红黑树的长度小于等于6,则会还原为单链表。在resize过程中,链表不会逆序。
为什么这里红黑树和单链表还要互相转换呢?因为这两者的侧重点不同。
- 单链表查找效率低,插入、删除效率高,适合少量数据
- 红黑树查找效率高,插入、删除效率低,适合大量数据
关于HashMap,里面值得讲的东西还挺多的。这里会出一篇文章全面讲解HashMap,以及JDK7、8中HashMap的异同。
1.1 红黑树定义¶
红黑树是每个结点都带有颜色属性的二叉查找树,颜色或红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
性质1. 结点是红色或黑色。
性质2. 根结点是黑色。
性质3. 所有叶子都是黑色。(叶子是NIL结点)
性质4. 每个红色结点的两个子结点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色结点)
性质5. 从任一节结点其每个叶子的所有路径都包含相同数目的黑色结点。
这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
是性质4导致路径上不能有两个连续的红色结点确保了这个结果。最短的可能路径都是黑色结点,最长的可能路径有交替的红色和黑色结点。因为根据性质5所有最长的路径都有相同数目的黑色结点,这就表明了没有路径能多于任何其他路径的两倍长。
2. HashSet¶
HashSet类的定义如下:
常用方法:
public int size()
public boolean isEmpty()
public boolean contains(Object o)
public boolean add(E e)
public boolean remove(Object o)
HashSet是基于HashMap实现的,底层采用HashMap来保存元素。它只关心key,value全部都是内部的一个PRESENT Object对象。
它的数据存储方面的特点与HashMap类似:
- HashSet是基于Set接口的非同步实现
- HashSet将对象存储在key中,且不允许key重复;且key可以为null
- HashSet的Value是固定的,为
PRESENTObject对象
3. HashTable¶
HashTable类的定义如下:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable
常用方法:
public synchronized int size()
public synchronized boolean isEmpty()
public synchronized boolean contains(Object value)
public boolean containsValue(Object value)
public synchronized boolean containsKey(Object key)
public synchronized V get(Object key)
public synchronized V put(K key, V value)
public synchronized V remove(Object key)
HashTable的特点如下:
- HashTable是基于Map接口的同步实现,可以理解为同步版本的HashMap
- HashTable中元素的key是唯一的,value值可重复
- HashTable中元素的key和value不允许为null,如果遇到null,则返回NullPointerException
- HashTable中的元素是无序的
HashTable在 JDK 8 中也是数组+单链表的形式,并没有运用到红黑树,可能是因为对于同步、非同步需求有更好的替代品的缘故。
- 对于同步要求,可以使用ConcurrentHashMap,其对写操作会分Segment进行加锁(JDK 7)或者对对应的桶加锁(JDK 8),这种处理方式比HashTable对所有数据加锁,显然效率高得多。
- 对于非同步要求,可以使用HashMap,尤其是 JDK 8 之后加入了红黑树,效率也会高得多。
4. LinkedHashMap¶
LinkedHashMap类的定义如下:
常用方法:
public int size()
public boolean isEmpty()
public V put(K key, V value)
public V get(Object key)
public boolean containsKey(Object key)
public boolean containsValue(Object value)
public V remove(Object key)
LinkedHashMap的特点如下:
- LinkedHashMap是基于Map接口的非同步实现
- LinkedHashMap是HashMap的子类
- LinkedHashMap中元素的key是唯一的,value值可重复;null键数据的存放和HashMap一样,也是放置到table[0]上
- LinkedHashMap是有序的
LinkedHashMap底层使用哈希表与双向链表来保存所有元素,它维护着一个运行于所有条目的双向链表,此链表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序,通过构造函数中的accessOrder字段控制,默认为false,即默认插入顺序
- 按插入顺序的链表:在LinkedHashMap调用get方法后,输出的顺序和输入时的相同,这就是按插入顺序的链表,默认是按插入顺序排序
- 按访问顺序的链表:在LinkedHashMap调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。简单的说,按最近最少访问的元素进行排序(类似LRU算法),链表头就是最近最少访问的元素。
LinkedHashMap 在其父类的 put方法中会调用 afterNodeAccess(e)方法;且重写了get、getOrDefault方法中,在方法中,如果accessOrder字段为true,会调用afterNodeAccess(e)方法。这样,就会将访问的节点e移动至链表的末尾。关于这个的应用,可以参考Glide中的LruCache的实现,Glide v4 源码解析(三)——深入探究Glide缓存机制——memoryCache介绍
LinkedHashMap有序的原因,是因为节点除了带next指针之外,还额外有before、after指针;next指针用在桶中,before、after 则用来统筹集合中所有元素的顺序。
5. LinkedHashSet¶
LinkedHashSet类的定义如下:
常用方法:
public int size()
public boolean isEmpty()
public boolean contains(Object o)
public boolean add(E e)
public boolean remove(Object o)
LinkedHashSet底层使用LinkedHashMap来保存所有元素,它继承于HashSet,其所有的方法操作上又与HashSet相同,因此LinkedHashSet的实现上非常简单,只提供了四个构造方法,并通过传递一个标识参数,调用父类的构造器,底层构造一个LinkedHashMap来实现,在相关操作上与父类HashSet的操作相同。
它的方面的特点与HashSet类似:
- LinkedHashSet是非同步的
- LinkedHashSet是有序的,按照插入顺序
- LinkedHashSet继承于HashSet,内部基于LinkedHashMap实现的,也就是说LinkedHashSet和HashSet一样只存储一个值,LinkedHashSet和LinkedHashMap一样维护着一个运行于所有条目的双向链表
6. ConcurrentHashMap¶
ConcurrentHashMap类的定义如下:
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable
常用方法:
public int size()
public boolean isEmpty()
public V put(K key, V value)
public V get(Object key)
public boolean containsKey(Object key)
public boolean containsValue(Object value)
public V remove(Object key)
ConcurrentHashMap有如下特点:
- ConcurrentHashMap基于双数组和链表的Map接口的同步实现
- ConcurrentHashMap中元素的key是唯一的、value值可重复
- ConcurrentHashMap不允许使用null值和null键
- ConcurrentHashMap是无序的
在 JDK 7 中,ConcurrentHashMap的数据结构为一个Segment数组,Segment的数据结构为HashEntry的数组,而HashEntry存的是我们的键值对,可以构成链表。因此,可以说是双数组+单链表的结构,写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment。 在 JDK 8 中,取消了Segment,直接采用HashEntry数组保存数据,采用table数组元素作为锁,从而实现了对每一桶数据进行加锁,进一步减少并发冲突的概率。且将原来的单链表变更为了单向链表+红黑树的结构。
7. TreeMap¶
TreeMap类的定义如下:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
常用方法:
public int size()
public boolean isEmpty()
public V put(K key, V value)
public V get(Object key)
public boolean containsKey(Object key)
public boolean containsValue(Object value)
public V remove(Object key)
TreeMap有如下特点:
- TreeMap间接实现了SortedMap接口、底层使用红黑树保存所有元素
- TreeMap是基于Map接口的非同步实现
- TreeMap中key是唯一的,value可以重复;对同一key的
put操作会使新的value替换并返回旧的value - TreeMap中不允许使用null键,但允许null值
- TreeMap中的元素是有序的
由于TreeMap基于红黑树实现,在排序时需要比较key的大小。因此,key必须实现Comparable接口或者在构造TreeMap时注入Comparator,后者的优先级更高。
Key实现Comparable接口的例子:
public final class Integer extends Number implements Comparable<Integer> {
...
public int compareTo(Integer anotherInteger) {
return compare(this.value, anotherInteger.value);
}
public static int compare(int x, int y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
...
}
构造TreeMap时注入Comparator的例子:
new TreeMap<Integer, String>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// TODO 替换成自己的比较方法
return o1.compareTo(o2);
}
});
8. TreeSet¶
TreeSet类的定义如下:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
常用方法:
public int size()
public boolean isEmpty()
public boolean contains(Object o)
public boolean add(E e)
public boolean remove(Object o)
TreeSet是基于TreeMap实现的,就和HashSet与HashMap的关系一样。由于TreeMap基于红黑树实现,在排序时需要比较key的大小。因此,TreeSet中的对象必须实现Comparable接口或者在构造TreeSet时注入Comparator,后者的优先级更高。
TreeSet有如下特点:
- TreeSet间接实现了SortedSet接口、底层基于TreeMap实现
- TreeSet是基于Set接口的非同步实现
- TreeSet将对象存储在key中,且不允许key重复
- TreeSet中对象不可以为null
- TreeSet中的元素是有序的
9. ArrayList¶
ArrayList类的定义如下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
常用方法:
public int size()
public boolean isEmpty()
public boolean contains(Object o)
public boolean add(E e)
public void add(int index, E element)
public E set(int index, E element)
public E get(int index)
public E remove(int index)
public boolean remove(Object o)
ArrayList 初始容量为 10,每次扩容增加旧容量的一半。
ArrayList有如下特点:
- ArrayList实现了List接口、底层使用数组保存所有元素,其操作基本上是对数组的操作
- ArrayList还实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问。
- ArrayList允许包括null在内的所有元素
- ArrayList是List接口的非同步实现
- ArrayList是有序的
10. LinkedList¶
LinkedList类的定义如下:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
常用方法:
// List
public int size()
public boolean isEmpty()
public boolean contains(Object o)
public boolean add(E e)
public void add(int index, E element)
public E set(int index, E element)
public E get(int index)
public E remove(int index)
public boolean remove(Object o)
// Deque
// 插到队列尾部
public boolean offer(E e)
// 弹出队列头部的数据
public E poll()
// 获取队列头部数据
public E peek()
// 插到队列头部
public boolean offerFirst(E e)
// 弹出队列尾部的数据
public E pollLast()
// 获取队列尾部数据
public E peekLast()
LinkedList有如下特点:
- LinkedList实现了List接口、底层基于双向链表实现的,所以它的插入和删除操作比ArrayList更加高效,但链表的随机访问的效率要比ArrayList差
- LinkedList实现了Deque接口,定义了双端队列的操作,双端队列是一种具有队列和栈的性质的数据结构,双端队列中的元素可以从两端弹出,其限定插入和删除操作在表的两端进行
- LinkedList允许包括null在内的所有元素
- LinkedList是List接口的非同步实现
- LinkedList是有序的
11. Vector¶
Vector类的定义如下:
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
常用方法:
public synchronized int size()
public synchronized boolean isEmpty()
public boolean contains(Object o)
public synchronized boolean add(E e)
public void add(int index, E element)
public synchronized E set(int index, E element)
public synchronized E get(int index)
public synchronized E remove(int index)
public boolean remove(Object o)
Vector有如下特点:
- Vector实现了List接口、底层使用数组保存所有元素,其操作基本上是对数组的操作
- Vector还实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问。
- Vector允许包括null在内的所有元素
- Vector是List接口的同步实现
- Vector是有序的
12. ArrayMap¶
ArrayMap 也实现了 Map 接口,常用接口与 HashMap 一致。
与 HashMap 不同的方法,该类专门新增了 append 方法在不验证的情况下将键值对添加到数组的后面,效率更高,适用于特定的场景。
ArrayMap 有以下特点:
- 底层数据结构基于两个数组:一个为保存 key hash 的
mHashes数组;另一个为保存键值对的mArray数组,键值对相邻储存。 mHashes数组是递增的,查找时使用二分查找进行查找;遇到 hash 冲突时,采用开放定址法,先往后遍历再往前遍历寻找。- 初始容量根据参数设置,默认为0。扩容时若小于 BASE_SIZE (4),则扩充为 BASE_SIZE;若小于 2 * BASE_SIZE,则扩为 2 * BASE_SIZE;否则扩容原来的一半。
- 针对size为BASE_SIZE*2和BASE_SIZE,设计了static的全局缓存,避免了频繁的申请内存。
注意
ArrayMap 和 SparseArray 都只适用于 1000 以下的数据规模。
13. SparseArray¶
SparseArray 实现的类似于 key 为 int 的 Map,这样查找时也可以使用二分查找。此外,SparseArray 也有 append 方法。
SparseArray 有以下特点:
- 底层数据结构基于两个数组:一个为保存 key 的
mKeys数组;另一个保存 value 的mValues数组。两者大小一样。 - key 为基本类型 int;其孪生类 (SparseIntArray) 等的 value 也是一个基本类型数组。这样避免了装箱拆箱。
- 初始容量为 10。扩容时若小于等于4,则扩容到8;否则扩容一倍。
- 延迟删除机制:删除键值对时将其 value 设为 DELETED,同时设置标志位 mGarbage,这表明需要进行垃圾回收。在其他操作时会检查标志位并进行内部的 gc 操作来将所有正常的数据复制到头部,类似于标记整理算法。
注意
ArrayMap 和 SparseArray 都只适用于 1000 以下的数据规模。
12. 总结¶
| 底层数据结构 | k唯一性 | k、v可空性 | 有序性 | 是否线程安全 | |
|---|---|---|---|---|---|
| HashMap | (JDK 7)数组+单链表,链表插入顺序为头插法 (JDK 8)数组+单链表+红黑树,链表插入顺序为尾插法 当链表的长度大于8时转换为红黑树; 在resize过程中,如果红黑树的长度小于等于6,则会还原为单链表 | 唯一 | k、v均可空; 但只允许一条k为空 | 无序 | 非线程安全 |
| LinkedHashMap | 继承至HashMap,唯一不同的是用带next的双向链表取代了单链表 | 唯一 | k、v均可空; 但只允许一条k为空 | 有序,分为插入顺序(默认)和访问顺序;由双向链表保存 | 非线程安全 |
| TreeMap | 红黑树 | 唯一 | k不可为空,v可为空 | 有序 | 非线程安全 |
| HashSet | 基于HashMap实现 | 唯一 | k可空,但只允许一条k为空; value固定为一个Object常量对象 | 无序 | 非线程安全 |
| LinkedHashSet | 继承至HashSet,基于LinkedHashMap实现 | 唯一 | k可空,但只允许一条k为空; value固定为一个Object常量对象 | 有序,分为插入顺序(默认)和访问顺序;由双向链表保存 | 非线程安全 |
| TreeSet | 基于TreeMap实现 | 唯一 | k不可为空 | 有序 | 非线程安全 |
| HashTable | 数组+单链表,链表插入顺序为头插法 | 唯一 | k、v均不可空 | 无序 | 线程安全 |
| ConcurrentHashMap | (JDK 7)双数组+单链表,链表插入顺序为头插法 (JDK 8)数组+单链表+红黑树,链表插入顺序为尾插法 当链表的长度大于8时转换为红黑树; 如果红黑树的长度小于等于6,则会还原为单链表 | 唯一 | k、v均不可空 | 无序 | 线程安全 |
| ArrayList | 数组 | v可空 | 有序 | 非线程安全 | |
| LinkedList | 双向链表,且实现了Deque接口 | v可空 | 有序 | 非线程安全 | |
| Vector | 数组,线程安全版本的ArrayList | v可空 | 有序 | 线程安全 |
注意,非线程安全的集合可以通过Collections的synchronizedCollection 、 synchronizedSet 、 synchronizedList 、 synchronizedMap等方法转换成线程安全的集合。其原理就是对每个操作都在同步代码块中执行。